
The FUDGE language
The FUDGE language is a research query language allowing the flexible querying of graph databases, which may be fuzzy or not. The FUDGE language allows to express preferences queries where preferencies may concern i) the content of the vertices of the graph and ii) the structure of the graph (which may include weighted vertices and edges when the graph is fuzzy).
A FUDGE seletion query adopts an approach à la CYPHER for querying a graph. CYPHER is an intuitive query language inspired from ASCII-art for graph representation, implemented in the Neo4j (crisp) graph database management system, in the spirit of the G language defined by Cruz, Mendelzon, and Wood in 1987. A selection query expresses a graph pattern. A pattern is a set of expressions of the form (n1:Type1)-[exp]->(n2:Type2) where n1, n2 are node variables, exp is an edge variable, label is a label of E, exp is a fuzzy regular expression, and Type1 and Type2 are node types. Such an expression denotes an edge or a path of the form exp going from a node n1 of type Type1 to a node n2 of type Type2.
An example of pattern is the following one:
(ar1:Article)-[part_of.series]->(s1),
(ar2:Article)-[part_of.series]->(s2),
(ar1)-[:creator]->(au1:Author),
(ar2)-[:creator]->(au1:Author)
The intuition is that, with such a pattern, one refers to every subgraphs of the database that are isomorphic to the pattern.
The pattern can contains additional conditions on variables like eg. ar2.year=2012.
In the FUDGE language, additional fuzzy conditions may be expressed,
- either concerning the content of vertices and edges, the year of an article may be “recent” where recent is a fuzzy term, or
- concerning the form of a path eg. a path going from an author to another one may by “short” where short is a fuzzy term.
A FUDGE query is composed of:
1) a list of DEFINE clauses for fuzzy term declaration. If a fuzzy term fterm corresponds to a trapezoidal function of the general form of Figure Trapezoidal function with the four positions (abscissa) A-a, A, B and B+b then the clause has the form DEFINE fterm AS (A-a,A,B,B+b). If fterm is a decreasing function like the term short of Figure Fuzzy term short then the clause has the form DEFINEDESC fterm AS (gamma,delta) (there is the corresponding DEFINEASC clause for increasing functions like eg. for the fuzzy term recent of Figure Fuzzy term short ).
2) a MATCH clause of the form MATCH pattern WHERE conditions where pattern is a fuzzy graph motif and conditions is the set of conditions attached to the pattern.
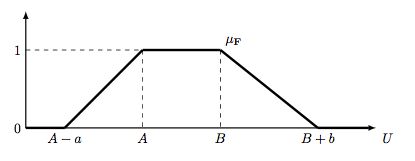
Trapezoidal function
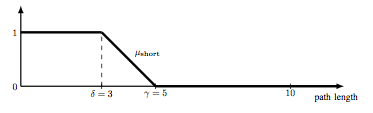
Fuzzy term short
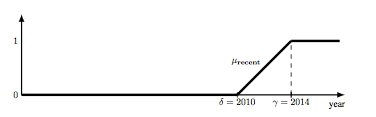
Fuzzy term recent
Here is an example of FUDGE query:
DEFINEDESC short AS (3,5)
DEFINEASC recent AS (2010,2014)
IN
MATCH
(ar1:Article)-[:PART_OF]->()-[:SERIES]->(s1),
(ar2:Article)-[:PART_OF]->()-[:SERIES]->(s2),
(ar1)-[:CREATOR]->(au1:Author),
(ar2)-[:CREATOR]->(au1:Author),
(au1)-[CONTRIBUTOR*| Length is short ]->(au2:Author)
WHERE s1.name='WWW' AND s2.name='Pods' AND ar2.year is recent
In this example, the DEFINEDESC clause of te first line defines the fuzzy term short, and the following clause defines the fuzzy term recent. The pattern in the MATCH/WHERE clause is the pattern above given, for which fuzzy conditions are added: a fuzzy confition on the year of the Article ar2 that has to be recent, and a fuzzy confition on the length (with the fuzzy graph definition of length) of the path of the form CONTRIBUTOR* going from au1 to au2 that has to be short.
What is SUGAR (formerly known as FUDGE prototype) ? How does it work ?
SUGAR stands for System based on fUzzy theory for (fuzzy) Graph dAtabases queRying. It is a proof-of-concept of the implementation of the FUDGE language. SUGAR is based on the Neo4j system that implements the CYPHER (crisp) query language. We extended interactive Neo4j REPL Console Rabbithole.
The evaluation of a FUDGE query is a three-stages one.
- A FUDGE transcriptor module translates the FUDGE fuzzy query into a CYPHER crisp one, which partly translates the fuzzy query. As an example, the translation of the FUDGE query example given below is:
MATCH
(ar1:Article)-[:PART_OF]->()-[:SERIES]->(s1),
(ar2:Article)-[:PART_OF]->()-[:SERIES]->(s2),
(ar1)-[:CREATOR]->(au1:Author),
(ar2)-[:CREATOR]->(au1:Author),
p1 = (au1)-[CONTRIBUTOR*]->(au2:Author)
WITH
REDUCE(length=0, edge IN relationships(p1)|length + 1/edge.fdegree) AS length_au1_au2_p1, ar1 AS ar1, s1 AS s1, ar2 AS ar2,s2 AS s2,au1 AS au1,au2 AS au2
WHERE
s1.name=’WWW’ AND s2.name=’Pods’ AND ar2.year>2010 AND length_au1_au2_p1<5.0
RETURN ar1, s1, ar2, s2, au1, au2, length_au1_au2_p1 AS calc_fuzzy_length_p1_short, ar2.year AS calc_fuzzy_ar2_year_recent - The query is sent to the crisp CYPHER query evaluator engine of Neo4j, which returns an answer that is an intermediate answer for FUDGE
- A FUDGE score calculator module performs the calculation of the satisfaction degree associated with each answer of the intermediate answer, cleans the answer and returns it to the client (web GUI)
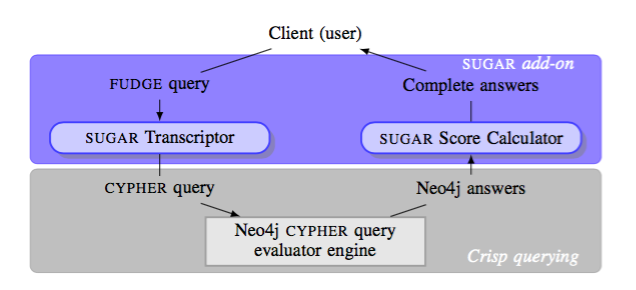
SUGAR architecture
Dowloading and installing SUGAR
Before all, please note that:
- SUGAR does not embed the full original Ne4j console Rabbithole as it is a proof-of-concept of a research work in progress, which focuses on extending the match operator.
- The software is still a prototype. For the moment, it only deals with well-formed FUDGE queries, without composition in patterns and only involving the Length property. Even with these simplifications, we believe that the prototype is sufficient to prove our concept.
- If you have any suggestion for improving this prototype or if you find a bug in the prototype, please do not hesitate to contact us.
In order to install and run locally the prototype on your computer, you have to
- Download the archive sugar_1.0.10.zip (approx. 42 MB)
- Enter in the sugar_1.0.10 folder (
cd sugar_1.0.9) - Build the project with Maven (which should be previously installed on your computer) by
mvn clean install exec:java - Open the application in a web browser at http://localhost:8080
Video – How to install and run SUGAR: SUGAR_install_and_run.mp4 (approx. 30 MB).
The SUGAR interface
The figure bellow is a screenshot of the application. The interface is composed of two frames:
- a central frame for vizualizing the graph and results of a query (the graph is overprinted, you can hide it by clicking on the Toggle Viz button)
- a small frame under the central one, for entering a FUDGE query (click on the Run button to execute the query)
When a query is executed, a table containing the result appears in the central frame (a row in this table corresponds to a subgrah answer) and nodes of the graph that belong to the answer are colored in red.
The interface is an extension of the Rabbithole interface, for taking FUDGE queries and results into account.

A screenshot of the FUDGE prototype interface
Logs trace the evaluation in an associated console, providing each intermediate result of the execution process viz. the crisp \cypher\/ query obtained after the transcription stage (output of the Transcriptor module), the result of the crisp query evaluation (an intermediate result containing additional information needed for the score calculation), and the final result obtained after the score calculation (output of the Score Calculator module). The logs also provide the execution time associated with each stage of the evaluation.
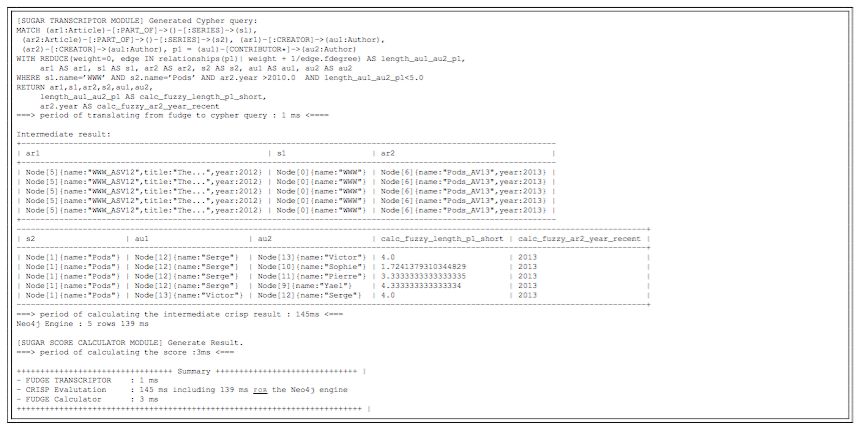
Execution trace in the SUGAR system
Acknowledgement
The Shaman team is deeply grateful to Mohamed Amine Daouma, Xuyang Zhang, David Maheo and Matthieu Biache who both intensively participated in the development of the prototype during their ENSSAT Master 1 internship in the Shaman team, and then Mohamed Amine Daouma alone for his ENSSAT Master 2 internship.