
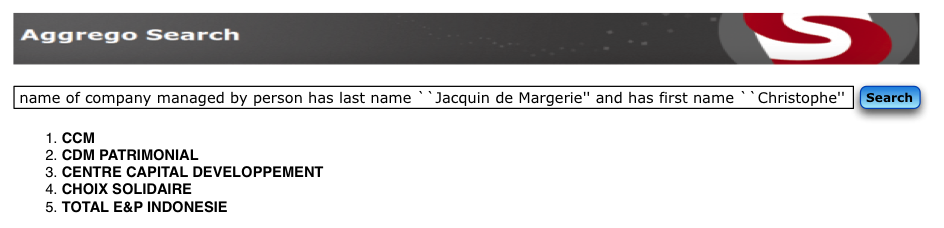
AggregoSearch
AGGREGO SEARCH offers a novel keyword-based query solu- tion for end users in order to retrieve precise answers from se- mantic data sources. Contrary to existing approaches, AGGREGO SEARCH suggests grammatical connectors from natural languages during the query formulation step in order to specify the meaning of each keyword, thus leading to a complete and explicit definition of the intent of the search. An example of such a query is name of person at the head of company and author of article about “business intelligence”. In order to help users formulate such connected keywords queries, a specific autocompletion strategy has been de- veloped. A translation of the user keyword query into SPARQL is performed on-the-fly during the interactive query construction pro- cess. For this demonstration, we show how AGGREGO SEARCH has been integrated on top of a mediation system to let users intu- itively define explicit and precise keyword queries in order to ex- tract knowledge distributed in heterogeneous large semantic data sources.
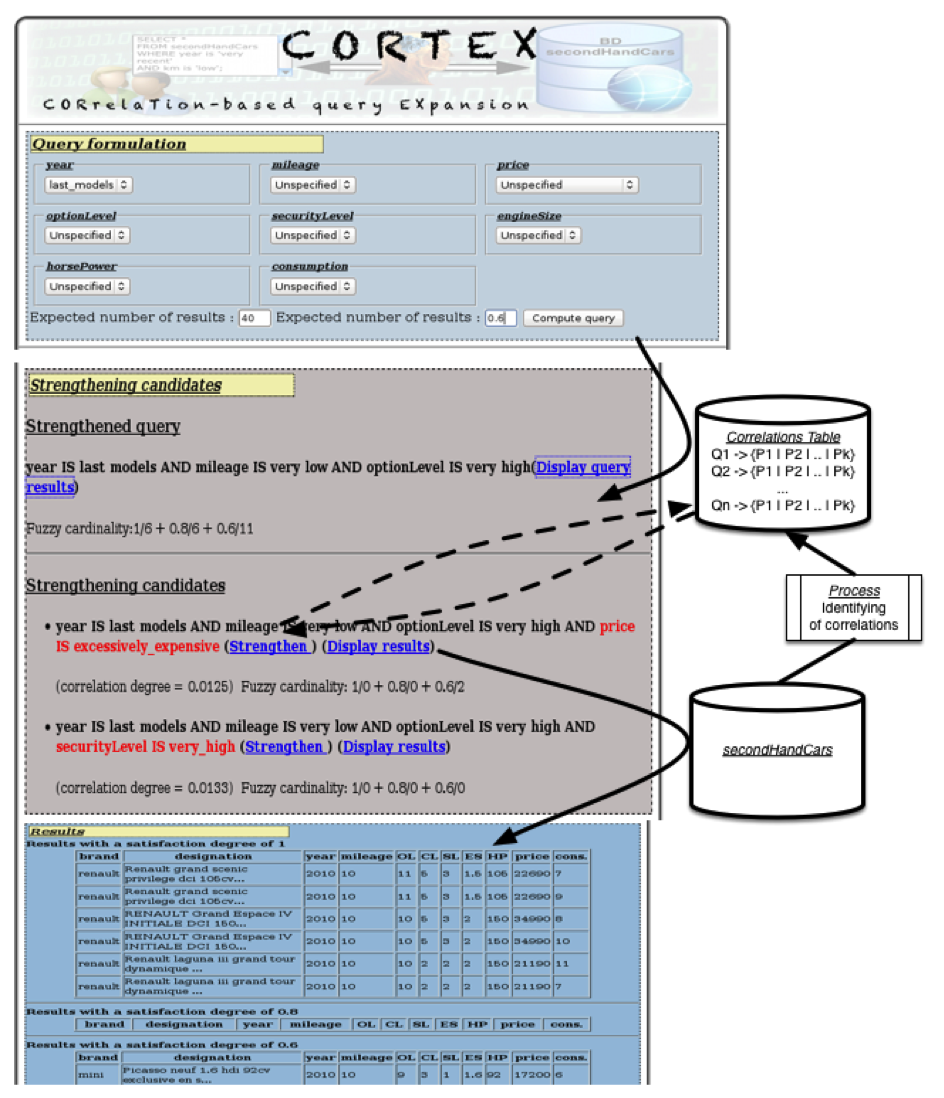
Cortex
Retrieving data from large-scale databases sometimes leads to plethoric an- swers especially when queries are under-specified. To overcome this problem, we propose to strengthen the initial query by adding new predicates. These predicates are selected among predefined ones principally according to their degrees of semantic correlation with the initial query. By this way, we avoid an excessive modification of its initial scope. Con- sidering the size of the initial answer set and the number of expected results specifed by the user, fuzzy cardinalities are used to assess the reduction capability of these correlated predefined predicates. This approach has been implemented as a research prototype to query a database containing 10.479 ads about second hand cars.
Lucifer
Lucifer tackles the problem of failing fuzzy queries, i.e. queries returning an empty set of answer.To help users revise their queries, Lucifer explains the orginal reasons of the failure by means of minimal failing subqueries. To efficiently solve this NP-Hard problem, Lucifer relies on a precomputation of fuzzy cardinality-based summary of the DB.
Musypher
The Musypher tool allows processing a music score encoded in the MEI format (XML file) and translating its content into a graph-based representation, in roder to be stored in a graph database. The output of the processing is a set of cypher dump queries, which may be either written on a file, either directly injected in a Noe4j database.
More information (download and first steps) here.
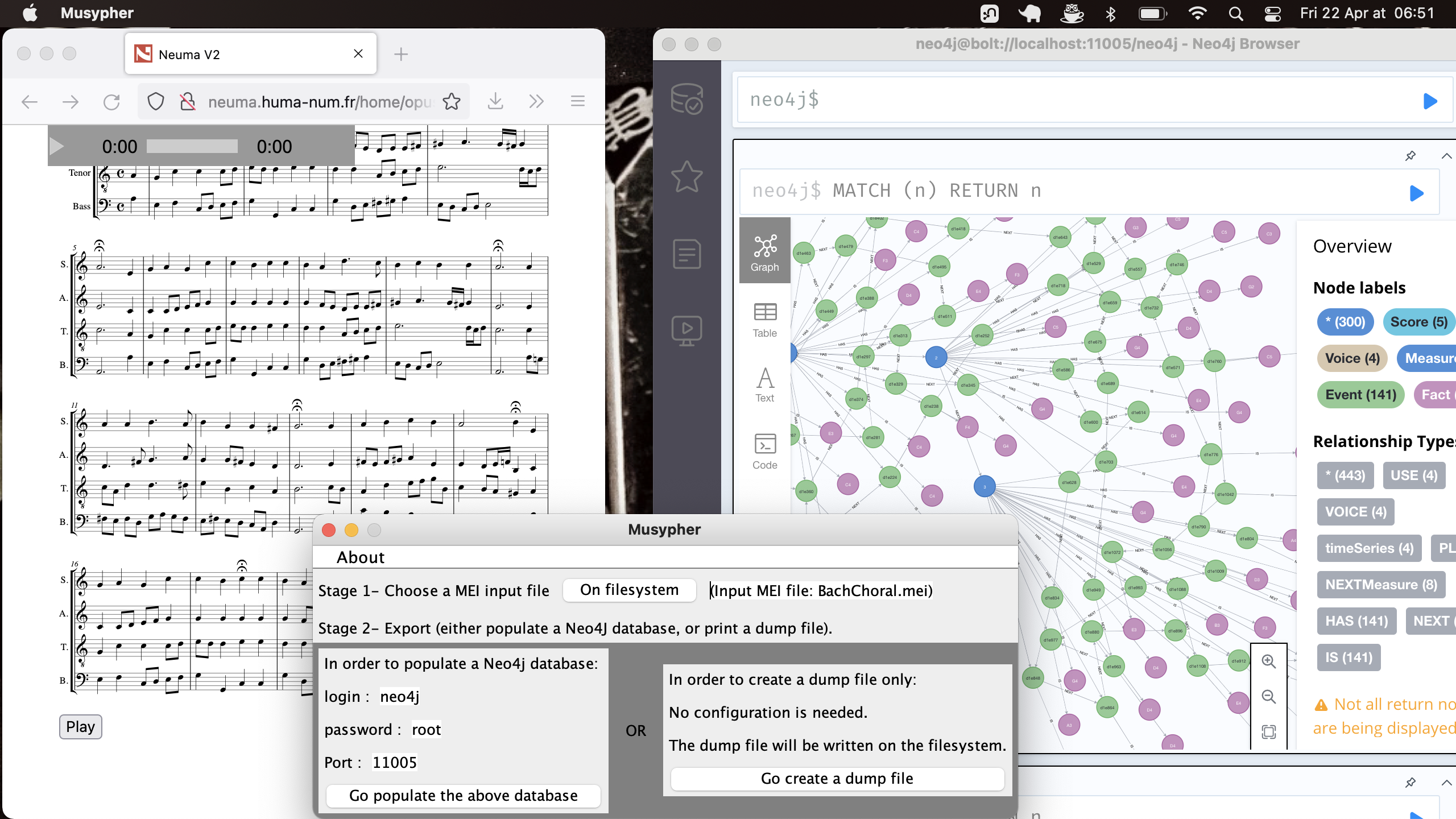
Screenshot of Musypher (in background: the NEUMA platform and Neo4j desktop)
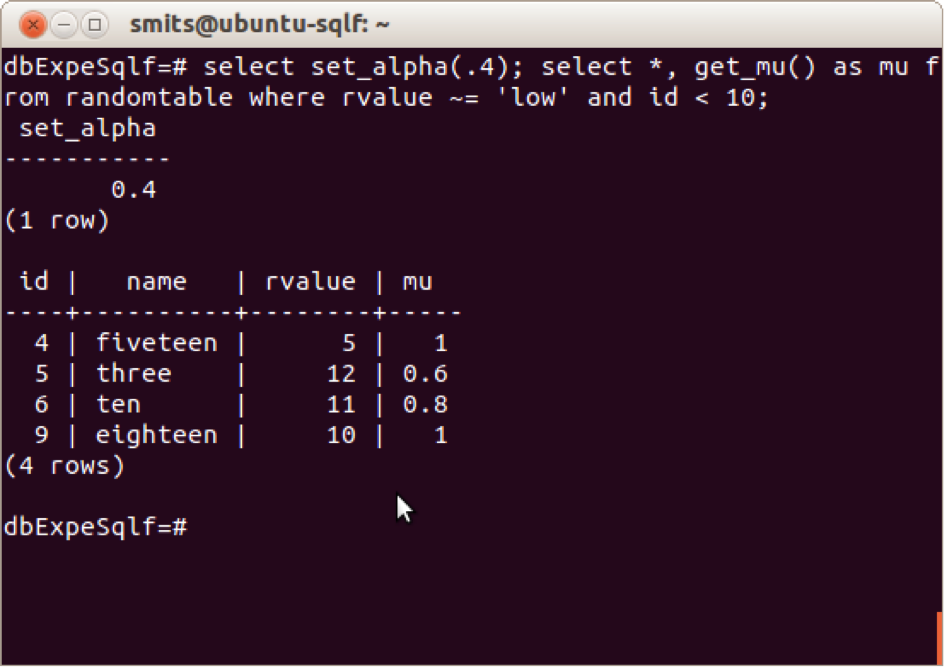
PostgreSQLf
PostgreSQLf is an extension of PostgreSQL that implements the functionalities necessary to the evaluation of fuzzy queries. The interests of such a mild coupling architecture lies in the fact that the fuzzy resulting relation is directly computed during the tuple selection phase which improves the overall performance of the fuzzy query execution process. Moreover, the definition of PostgreSQLf as an external module (PGXN) that can be loaded at runtime by PostgreSQL makes easier the maintenance and code distribution. Implemented with functions and procedures written in C or PL/PGSQL, the current version of PostgreSQL f offers the following functionalities:
- Definition of fuzzy predicates over numerical attributes
- Definition of fuzzy predicates over categorical attributes
- Introduction of fuzzy conditions
- Application of modifiers
- Conjunctions and disjunctions
- Calibration of the results with thresholds
- Aggregation of predicates with fuzzy quantifiers
- Definition and use of gradual operators
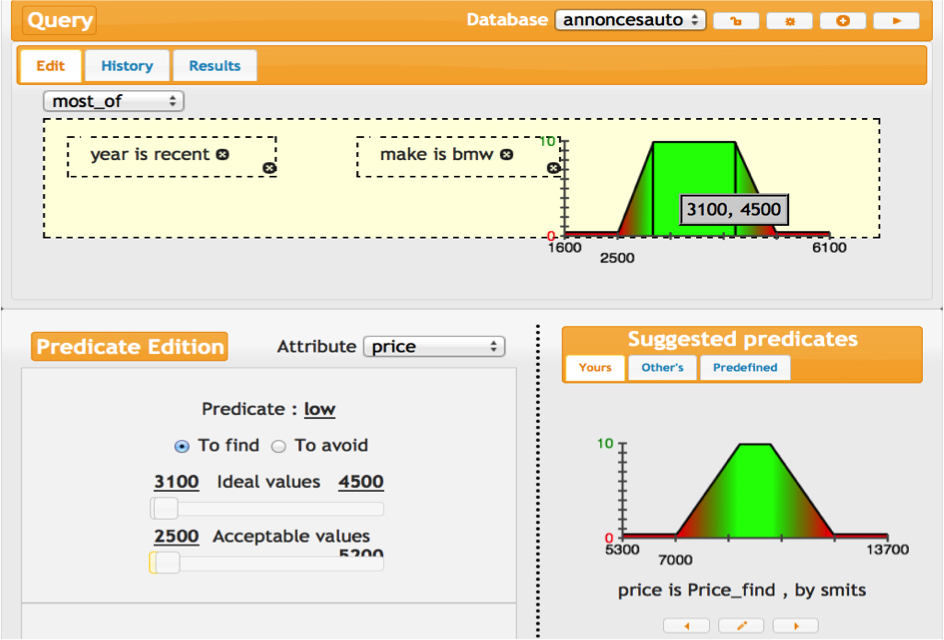
ReqFlex
ReqFlex is a user interface to the definition of fuzzy queries that may then be interpreted PostgreSQLf. ReqFlex focuses on the intuitive definition of queries composed of a projection and a selection part addressed to a universal relation that may be a view over joined tables.
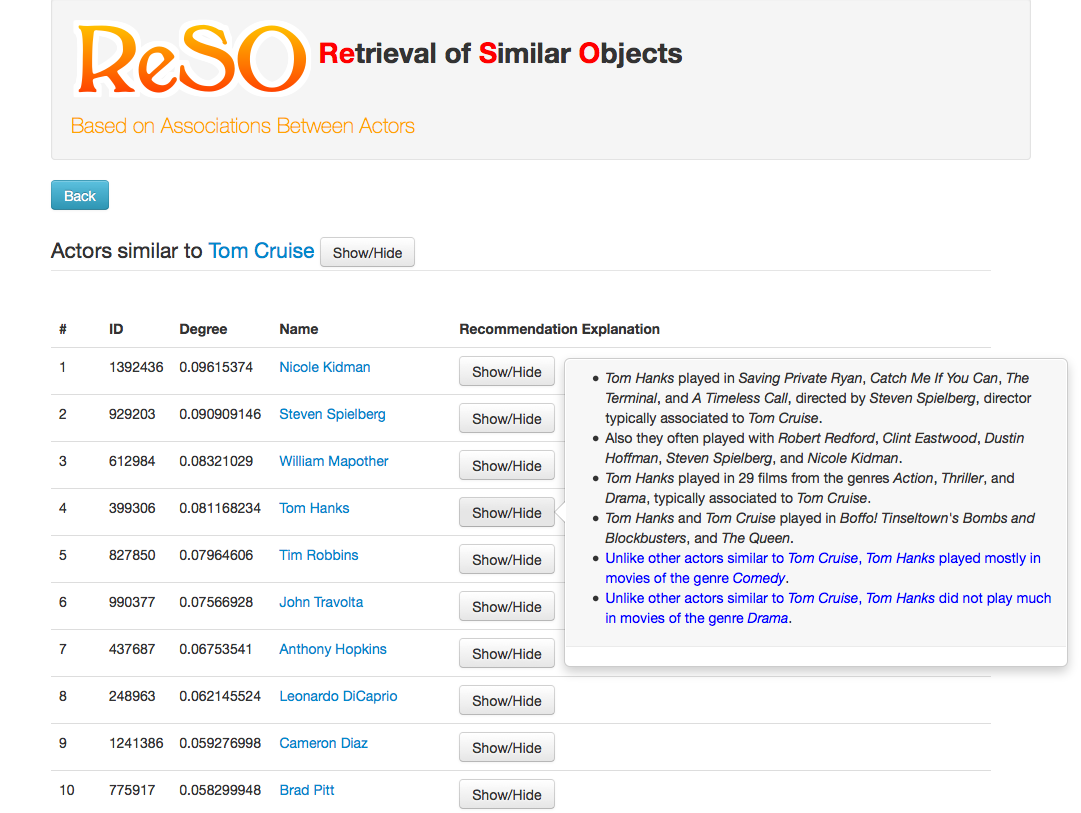
ReSO: Retrieval of Similar Objects
This prototype provides actor recommendations to the user, based on an actor and a few parameters. These recommendations are based on typicality and similarity criteria such as actors, genres and directors. The user can choose how important each criterion is to compute the recommendations, as well as which matching measure will be used to order the results. Explanations as to why each actor is returned are then proposed to the user, and differences between recommended actors are highlighted. The data used came from the IMDb database.
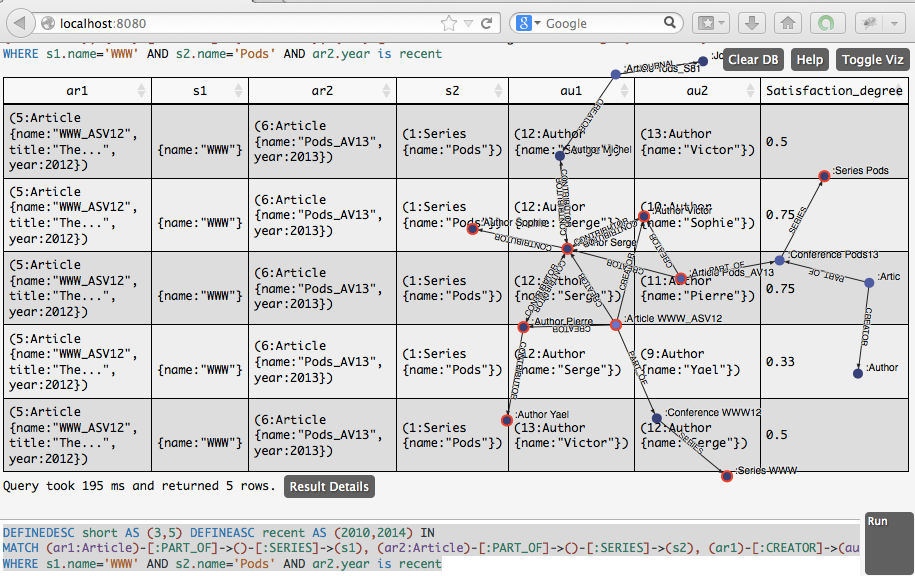
SUGAR (System based on fUzzy theory for (fuzzy) Graph dAtabases queRying)
The FUDGE language is a research query language allowing the flexible querying of graph databases, which may be fuzzy or not. The FUDGE language allows to express preferences queries where preferencies may concern i) the content of the vertices of the graph and ii) the structure of the graph (which may include weighted vertices and edges when the graph is fuzzy). SUGAR is a prototype, based on Ne4j, implementing the FUDGE language.
More information here.
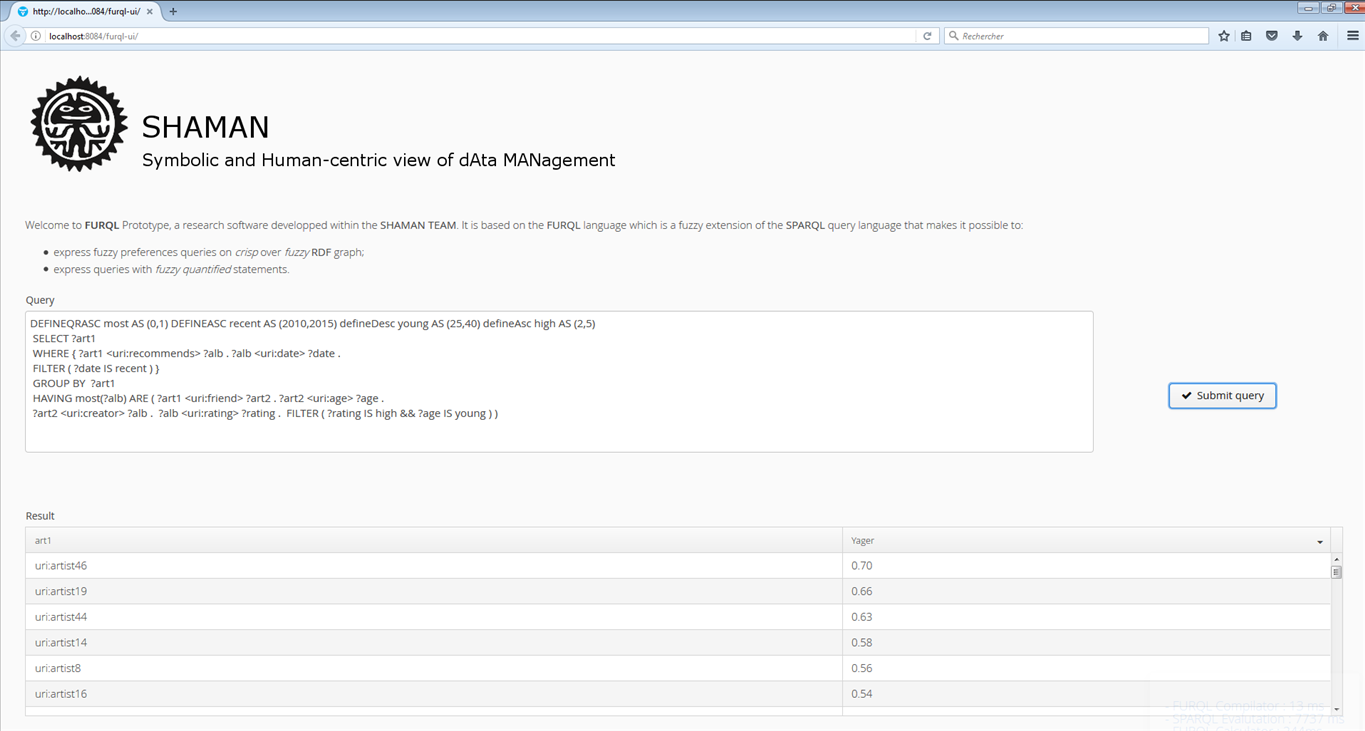
SURF
A system implementing a fuzzy extension of the SPARQL query language allowing to deal with fuzzy preferences over fuzzy RDF data.
More information here.
TAMARI (Quality Alerts Management in Graph Databases using Rabbithole)
A quality-aware extention for graph pattern queries.
More information here.
